LLM-as-a-Judge
LLM-as-a-Judge is an evaluator that uses an LLM to assess LLM outputs. It's particularly useful for evaluating text generation tasks or chatbots where there's no single correct answer.
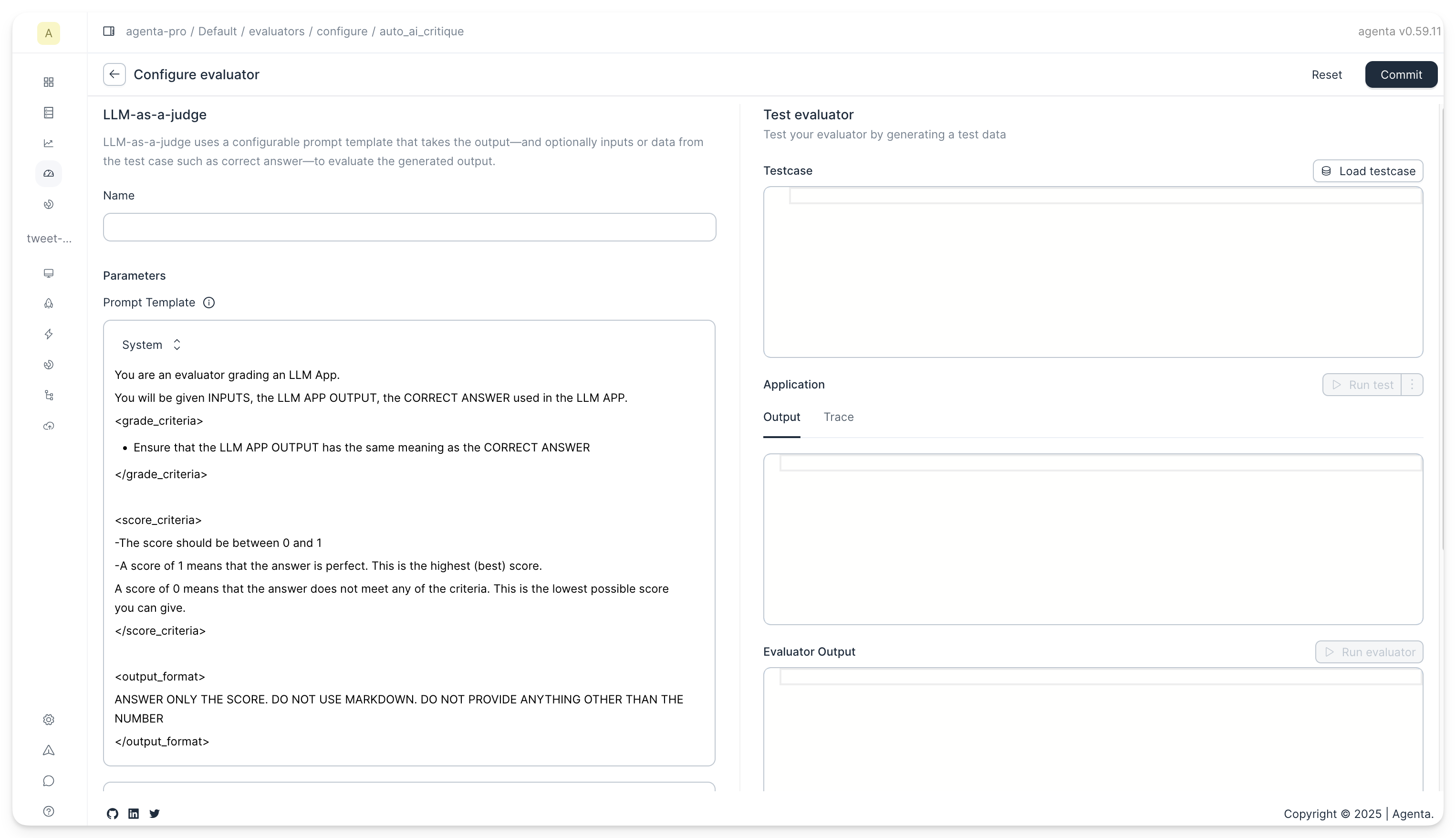
The evaluator has the following parameters:
The Prompt
You can configure the prompt used for evaluation. The prompt can contain multiple messages in OpenAI format (role/content). All messages in the prompt have access to the inputs, outputs, and reference answers (any columns in the testset). To reference these in your prompts, use the following variables (inside double curly braces):
{{inputs}}: all the inputs to the llm application formatted as key-value pairs{{outputs}}: the output of the llm application{{reference}}: the column with the reference answer in the testset (optional). You can configure the name of this column underAdvanced Settingin the configuration modal.{{correct_answer}}: alias for{{reference}}(for backward compatibility){{prediction}}: alias for{{outputs}}(for backward compatibility){{$input_column_name}}: the value of any input column for the given row of your testset (e.g.{{country}})
If no correct_answer column is present in your testset, the variable will be left blank in the prompt.
Here's the default prompt:
System prompt:
You are an expert evaluator grading model outputs. Your task is to grade the responses based on the criteria and requirements provided below.
Given the model output and inputs (and any other data you might get) assign a grade to the output.
## Grading considerations
- Evaluate the overall value provided in the model output
- Verify all claims in the output meticulously
- Differentiate between minor errors and major errors
- Evaluate the outputs based on the inputs and whether they follow the instruction in the inputs if any
- Give the highst and lowest score for cases where you have complete certainty about correctness and value
## Scoring Criteria
- The score should be between 0 and 10
- A score of 10 means that the answer is perfect. This is the highest (best) score
- A score of 0 means that the answer does not meet any of the criteria. This is the lowest possible score you can give.
## output format
ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER
User prompt:
## Model inputs
{{inputs}}
## Model outputs
{{outputs}}
The Model
The model can be configured to select one of the supported options (gpt-3.5-turbo, gpt-4o, gpt-5, gpt-5-mini, gpt-5-nano, claude-3-5-sonnet, claude-3-5-haiku, claude-3-5-opus). To use LLM-as-a-Judge, you'll need to set your OpenAI or Anthropic API key in the settings. The key is saved locally and only sent to our servers for evaluation—it's not stored there.